When Every Department Defines ‘Customer’ Differently
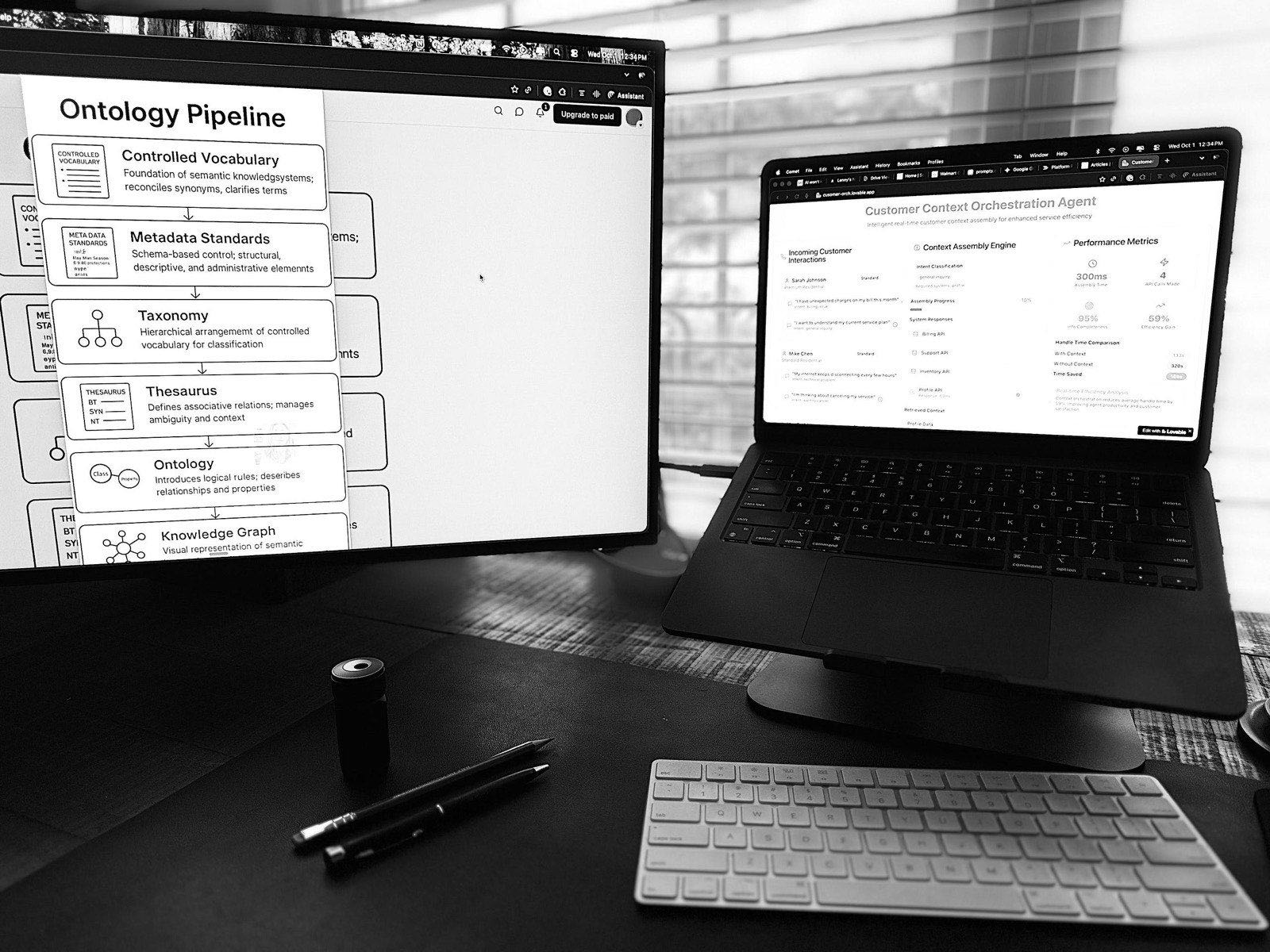
If you’ve followed my writing, you know I’m convinced the single most important concept any company should build their business around is the customer. Lately I’ve been trying to take my customer-based context engineering approach and figure out how that works as an AI agent. To that end I built a prototype for a customer context orchestration system (the prototype is live at https://cusomer-orch.lovable.app/ if you’re interested).
The idea is to build an orchestration agent that can load all of the necessary context around a customer’s service when a support agent takes a call, instantly assembling recent events and context from billing, support history, product usage, whatever. No hunting through multiple systems. No asking customers to repeat information the company already has.
I like the idea, but building it helped me see that executing this at any kind of scale will be harder than I thought it would be.
The Centralized Approach Most Product Leaders Inherit
When I started thinking about how to organize customer context for AI, I looked at what seemed like best practice. Jessica Talisman’s Ontology Pipeline methodology represents the sophisticated end of this work — starting with controlled terms, building hierarchies, creating relationships, developing knowledge networks. It’s grounded in 25+ years of information architecture and produces real results.
This approach makes intuitive sense. Good systems should have shared understanding. Everyone should agree on what things mean. Get the definitions right up front, build your architecture on that foundation, and everything downstream works smoothly.
The problem is that this requires centralized decision-making about business meaning. Someone (or a committee) has to decide what “qualified lead” means for the entire company. Those decisions get baked into system architecture, and everyone has to live with them.
I figured this would work for my customer context agent. It didn’t.
I Do Not Think That Means What You Think It Means
How do you handle “qualified lead” when Sales defines it one way and Marketing defines it another?
Building the prototype made it clear that different teams define the same terms differently. How should the system handle a customer flagged as “high value” by billing but “problematic” by support? Which definition should drive the AI’s recommendations?
The design works when teams share operational context. Sales and marketing could align on lead definitions because they work toward similar goals. This is what Master Data Management practices try to achieve in big companies. But it’s really difficult to create a single set of definitions that span all departments when they have fundamentally different operational needs.
Support needs to track “problematic” customers because that drives resource allocation and escalation procedures. Billing needs to track “high value” customers because that drives contract renewal and expansion strategies. Both definitions are operationally correct for their contexts.
Someone has to make sense of these conflicts systemically. Product leaders are positioned to see across operational boundaries in ways that specialists within individual domains can’t. They understand how billing’s need to track contract value relates to support’s need to manage escalations, and can think through how both perspectives should inform the AI’s behavior in different contexts. That cross-functional perspective (understanding how different parts of the business operate and need to work together) is what makes this a product challenge that requires collaboration with data architecture to implement.
A Different Approach Taking Shape
Instead of forcing consensus, what if systems could maintain their operational definitions while still sharing intelligence?
This is what I’ve been exploring with customer-based context engineering, building thin indexes that preserve how different systems understand customers rather than forcing them to converge. The customer becomes the organizing principle, but each system maintains its operational context.
Rather than deciding whether a customer is “high value” or “problematic,” I worked to build the prototype so it would understand that billing considers them high value AND support considers them problematic. Both perspectives stay intact and inform better decision-making.
Support’s definition includes context about technical complexity, communication patterns, and resource requirements. Billing’s definition includes payment history, contract terms, and expansion potential. Neither gets flattened or compromised to fit a centralized schema.
The Tradeoff
This federated approach requires ongoing maintenance. Those semantic bridges between systems need active management as operational contexts evolve. It trades architectural simplicity for operational effectiveness, maintaining bridges between definitions is more work than enforcing a single centralized schema.
But when your business contexts evolve faster than you can maintain centralized definitions, this approach preserves the operational meaning that makes individual systems effective. You’re not fighting against how teams actually work.
An AI agent designed this way accesses both perspectives without forcing artificial consensus. It can surface billing’s context when the user needs revenue insights, support’s context when troubleshooting issues, or both when the situation demands cross-functional understanding.
Data Becomes the Product
The timing matters here. We’re heading toward a world where interfaces are generated locally and AI agents operate autonomously on behalf of users. When I needed to reconcile transactions across my bank and two credit cards recently, I dumped CSVs into a spreadsheet because each system used different column names. Soon, I’ll just tell my local AI “show me spending across these three sources” and it’ll generate the interface I need. Or an AI agent will do it automatically when preparing my tax information.
When that happens, businesses lose control over the presentation layer entirely. What remains is your data and your capabilities exposed through APIs. The semantic clarity of that data (whether it’s well-documented, whether conflicting definitions are preserved rather than hidden, whether the bridges between operational contexts are maintained) becomes your product.
This connects to what I wrote about in “Context Is What Holds the System Together.” Context needs to flow between systems, but forcing everyone to use the same definitions makes it harder for teams to solve their individual problems and workflows. The federated approach builds infrastructure for a world where businesses can’t control how their capabilities get consumed.
More from Context Engineering

Context Engineering, One Year Later
A year after coining context engineering, the idea evolved from a simple observation into infrastructure, tooling, and a knowledge management discipline.

Everyone is Talking About Context Engineering
Context engineering is bigger than prompt optimization. It’s a discipline of preserving meaning across boundaries — practiced by historians, lawyers, and translators long before AI.

Customer-based Context Engineering
Most companies organize data around internal systems, not customers. Customer-based context engineering creates a unified index across systems without replacing them.